Kubeflow vs Airflow:
Which Pipeline Tool Should You Use for ML?
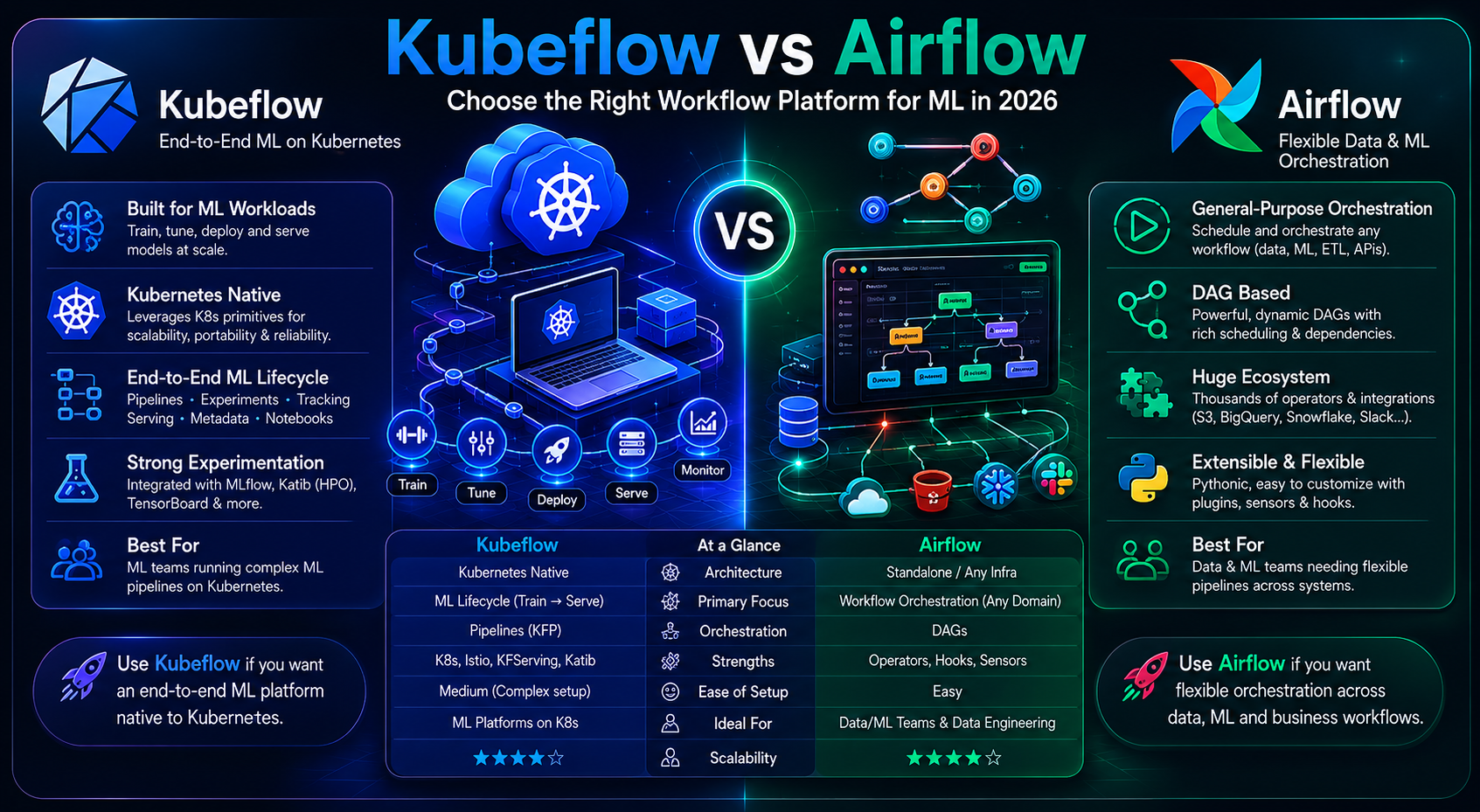
Kubeflow vs Airflow verdict: Airflow wins when your ML work is inside a larger data pipeline and your team has no Kubernetes experience. Kubeflow wins when you need distributed GPU training or are building a dedicated ML platform.
1. What is Apache Airflow?
💰 Free (Open Source)
When comparing Kubeflow vs Airflow, understanding each tool’s origin is critical. Airflow orchestrates complex, multi-step data pipelines. You write Python DAGs, and Airflow handles scheduling, retries, logging, and dependencies. It runs anywhere — a single VM, Docker Compose, or Kubernetes.
Best for: Teams that need flexible orchestration across data, ML, and business workflows.
2. What is Kubeflow?
💰 Free (Open Source)
In the Kubeflow vs Airflow debate, Kubeflow takes the ML-native crown. Kubeflow runs ML workflows natively on Kubernetes. It includes pipelines, notebooks (JupyterHub), distributed training (TFJob, PyTorchJob), hyperparameter tuning (Katib), and model serving (KServe).
Best for: ML teams running complex ML pipelines on Kubernetes.
3. Architecture: How They Actually Work Under the Hood
Understanding the Kubeflow vs Airflow execution model is the fastest way to understand why they suit different use cases.
⚡ Airflow
- Scheduler polls metadata DB for DAGs to run
- Workers pick up tasks via Celery or K8s executor
- Tasks share the worker’s Python environment
- State stored in PostgreSQL or MySQL
☸️ Kubeflow
- Pipelines compiled to Argo Workflow CRDs
- Each step becomes its own Kubernetes Pod
- Per-step container isolation — full dependency control
- State stored in etcd via Kubernetes CRDs
4. Airflow ML Pipeline in Practice
Here’s what a real ML training pipeline looks like in Airflow when comparing Kubeflow vs Airflow for actual implementation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from airflow import DAG from airflow.operators.python import PythonOperator from datetime import datetime def preprocess_data(**kwargs): print("Preprocessing 10,000 rows of data...") def train_model(**kwargs): print("Training model with 0.94 accuracy") with DAG( "ml_training_pipeline", start_date=datetime(2026, 1, 1), schedule_interval="0 2 * * *", ) as dag: preprocess = PythonOperator(task_id="preprocess", python_callable=preprocess_data) train = PythonOperator(task_id="train", python_callable=train_model) preprocess >> train |
5. Kubeflow Pipeline in Practice
Here’s the equivalent Kubeflow vs Airflow pipeline using Kubeflow Pipelines SDK v2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from kfp import dsl from kfp.dsl import component @component(base_image="python:3.11-slim") def preprocess(): print("Preprocessing complete") @component(base_image="pytorch/pytorch:2.1.0-cuda11.8-cudnn8") def train(): print("Training complete on GPU") @dsl.pipeline(name="ml-training-pipeline") def ml_pipeline(): preprocess_task = preprocess() train_task = train() train_task.after(preprocess_task) train_task.set_accelerator_type("nvidia.com/gpu") train_task.set_accelerator_limit(1) |
6. Head-to-Head Comparison: Kubeflow vs Airflow
Here’s how Kubeflow vs Airflow stack up across key features for ML teams in 2026:
| Feature | Apache Airflow | Kubeflow |
|---|---|---|
| Primary audience | Data engineers | ML engineers |
| ML-native features | ✗ No | ✓ Yes (tracking, serving, HPO) |
| Kubernetes required | ✓ Not required | ✗ Required |
| GPU scheduling | ~ Limited | ✓ Native |
| Setup time | ✓ Hours | ✗ Days to weeks |
| Learning curve | ✓ Moderate | ✗ Steep (K8s + YAML) |
| Infrastructure overhead | ✓ Minimal | ✗ Significant |
7. When to Choose Airflow
Airflow is the right choice when your ML work doesn’t live in isolation — when training a model is one step inside a larger data workflow.
- Your team already runs Airflow for data engineering
- ML pipelines mix with non-ML steps: ETL, reporting, alerting
- Your team has no Kubernetes experience or access
- You need something working this week, not this month
- Your models train on single machines — no multi-GPU training
8. When to Choose Kubeflow
Kubeflow pays off when you’re building a dedicated ML platform with proper container isolation, native GPU access, and a unified training-to-serving lifecycle.
- Your team already runs on Kubernetes (GKE, EKS, AKS)
- You need distributed training across multiple GPU nodes
- You want built-in hyperparameter tuning without adding another tool
- You’re building a shared internal ML platform across multiple teams
- Different pipeline steps need completely different container environments
9. Can Airflow and Kubeflow Work Together?
Yes — and this is actually one of the best deployment patterns for larger teams. Airflow owns the data side, Kubeflow owns the ML side.
Integration Pattern: Airflow handles data engineering and ETL, then triggers Kubeflow pipelines for distributed GPU training via KubernetesPodOperator or API call. This lets each tool do what it’s best at — no compromises.
10. The Verdict: Kubeflow vs Airflow
11. Frequently Asked Questions
Is Kubeflow better than Airflow for ML?
Kubeflow is more purpose-built for ML — it includes experiment tracking, distributed training, and model serving out of the box. But in the Kubeflow vs Airflow comparison, “better” depends on your situation. If you don’t have Kubernetes, Airflow is objectively better.
Can I use Airflow without Kubernetes?
Yes — this is one of Airflow’s biggest advantages. Airflow runs on a single VM or Docker Compose. Kubeflow has no equivalent lightweight path.
How long does it take to set up Kubeflow vs Airflow?
Airflow: 30 minutes local, hours production. Kubeflow: requires K8s cluster (days to provision) plus 1-3 days for full deployment.
Can Airflow and Kubeflow work together?
Yes. Airflow handles data engineering and ETL, then triggers Kubeflow pipelines for distributed GPU training.
#MLPipelineOrchestration
#ApacheAirflow
#KubeflowTutorial
#MLOps
📚 Related Reading: MLflow vs ClearML • 10 Best MLOps Tools • MLOps Roadmap 2026
📖 External resources: Apache Airflow Docs • Kubeflow Official Site • Airflow GitHub • Kubeflow GitHub