How to Become an ML Engineer in 2026 — The Complete Step-by-Step Roadmap
MLOps demand is at an all-time high, salaries are strong, and the learning path has never been clearer. This roadmap takes you from absolute beginner to job-ready ML engineer — in 6 months, with free resources and real portfolio projects at every phase.
Figure 1: AI/ML job salaries in 2026 — ML Engineer roles consistently pay $150k+
Your 6-month learning path
0 → job-ready- Phase 0Mindset & PrerequisitesMonth 0–1
- Phase 1Machine Learning FundamentalsMonth 1–2
- Phase 2Experiment TrackingMonth 2–3
- Phase 3Model DeploymentMonth 3–4
- Phase 4Pipeline OrchestrationMonth 4–5
- Phase 5Production MonitoringMonth 5–6
- Phase 6Advanced Topics (LLMOps & Beyond)Month 6+
MLOps — machine learning operations — is the discipline of building, deploying, and maintaining ML systems in production. It bridges the gap between a data scientist training a model in a notebook and that model actually serving predictions to real users, reliably, at scale, 24/7.
In 2026, every serious ML team has at least one MLOps engineer. The role didn't meaningfully exist five years ago. Today it's one of the fastest-growing technical roles in tech, with median salaries sitting firmly above $130,000 in the US.
How to use this guide: Read each phase, then do the hands-on project before moving on. Employers don't care what you've read — they care what you've built. The projects at each phase become your portfolio.
Mindset & Prerequisites
Before you write a single line of ML code, you need three non-negotiable foundations: Python fluency, command-line comfort, and Git. These aren't optional extras — every MLOps tool you'll use assumes all three.
Python Fundamentals
Functions, classes, list comprehensions, virtual environments. You don't need to be a Python expert — you need to be comfortable.
Command Line (Bash)
Navigate directories, run scripts, pipe commands. Every MLOps tool you'll use lives in the terminal.
Git & GitHub
Commit, branch, pull request. Your model code needs version control just like your application code.
Phase 0 project: Set up a Python virtual environment, write a script that reads a CSV file, processes the data, and saves a result. Commit it to a GitHub repo with a proper README. You'll use this pattern hundreds of times.
Machine Learning Fundamentals
You don't need a PhD in statistics to do MLOps. But you absolutely need to understand what you're deploying and monitoring. This phase covers the core ML concepts every ML engineer must know cold.

Figure 2: Scikit-learn — your first stop for ML fundamentals
Supervised vs. Unsupervised Learning
Classification, regression, clustering — what problems each solves and when to use them.
Train a Real Model with Scikit-learn
Load a dataset, split it, train a RandomForest, evaluate it. Hands-on is non-negotiable.
Evaluation Metrics
Accuracy, precision, recall, F1-score, AUC-ROC. Understand not just what they mean, but when each one matters.
Train/Test Split & Cross-Validation
How to avoid data leakage and build models that generalize.
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import classification_report X, y = load_iris(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) model = RandomForestClassifier(n_estimators=100) model.fit(X_train, y_train) scores = cross_val_score(model, X, y, cv=5) print(f"CV Accuracy: {scores.mean():.4f} ± {scores.std():.4f}") print(classification_report(y_test, model.predict(X_test)))
Phase 1 project: Train a classifier on a Kaggle dataset of your choice. Write a short analysis explaining your metric choices. Push it to GitHub.
Experiment Tracking with MLflow
Here's the problem that kills most ML teams at scale: you train 50 models across a week of experiments. Which parameter combination produced your best result? Which code version? Without experiment tracking, you can't answer any of those questions.
Log Parameters & Metrics
Every hyperparameter and every evaluation metric — automatically tracked.
Model Artifacts
Save the actual model file with every run. Load it anywhere later.
Compare & Reproduce
Side-by-side run comparison in the MLflow UI. Re-create any past run exactly.
Deep dive: Read our complete MLflow Tutorial (Article #9) for a full hands-on walkthrough.
Phase 2 project: Take your Phase 1 model and wrap it in MLflow tracking. Run at least 10 experiments with different hyperparameters. Document your best run and explain why it won.
Model Deployment
A model that lives in a Jupyter notebook doesn't generate value. Deployment is how you take a trained model and make it available to applications, users, and downstream systems.
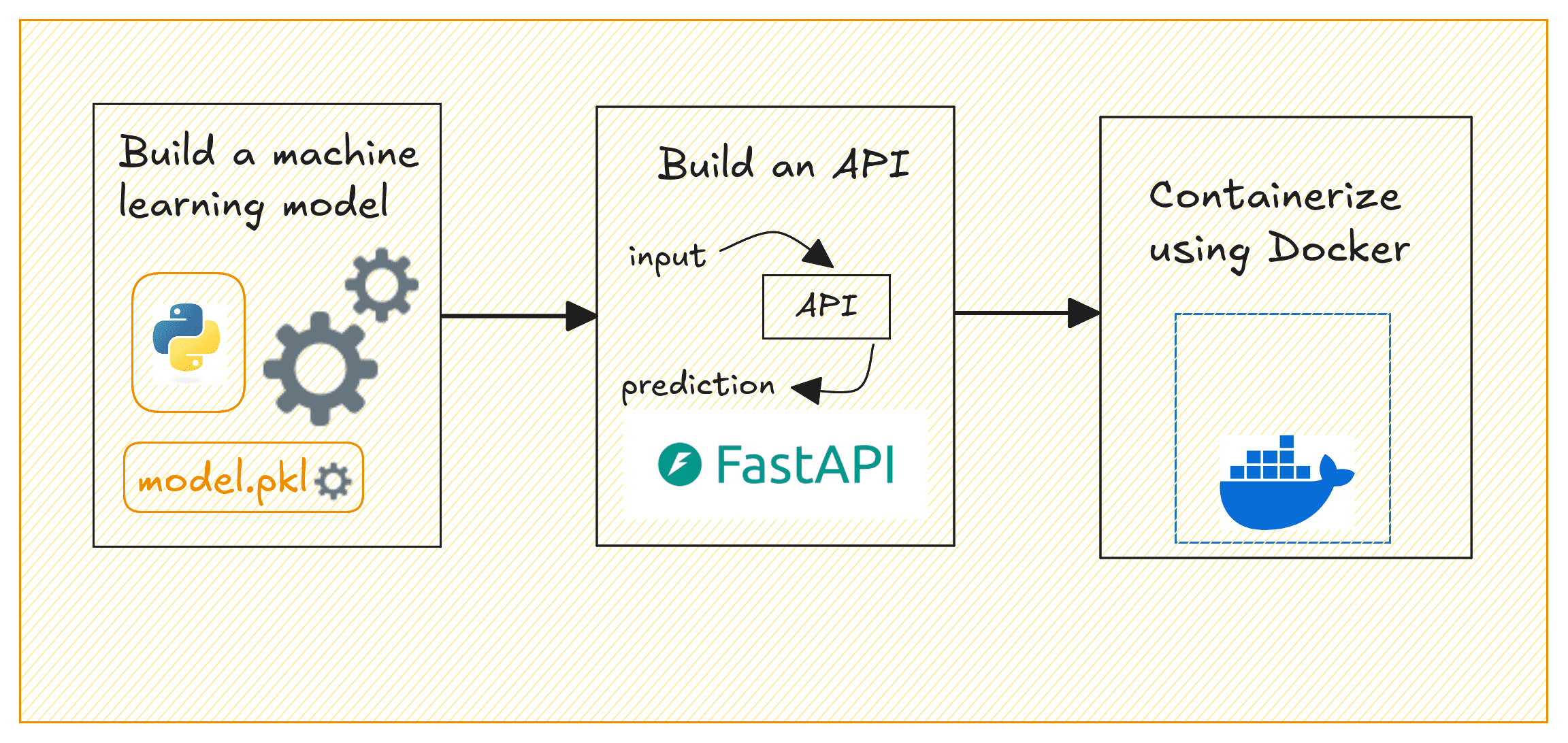
Figure 3: Model deployment workflow — from trained model to production API
FastAPI Recommended
- Modern Python — async by default
- Auto-generates API documentation
- Industry standard for ML serving in 2026
Flask
- Simpler, more beginner-friendly
- Massive ecosystem of tutorials
- Good for prototypes and internal tools
Phase 3 project: Wrap your Phase 2 model in a FastAPI server, containerize it with Docker, and run it locally. Test the endpoint with curl or Postman. Document the API in your README.
Pipeline Orchestration
Manually running scripts to retrain and redeploy models doesn't scale. ML pipelines automate the entire workflow: data ingestion → feature engineering → training → evaluation → deployment.
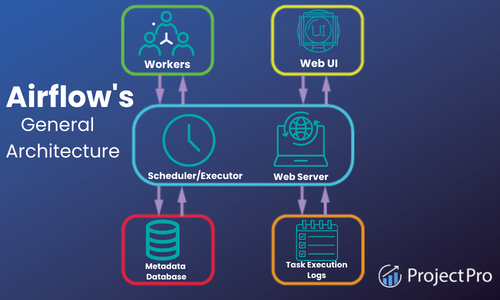
Figure 4: Apache Airflow architecture — DAG-based workflow orchestration
Apache Airflow
- Industry-standard for data pipelines
- Massive community and plugin ecosystem
- Python-native DAG definitions
Kubeflow Pipelines ML-native
- Purpose-built for ML workflows on Kubernetes
- Native artifact tracking and lineage
- Used by Google, Spotify, Salesforce
Common mistake: New MLOps engineers try to jump to Kubernetes too early. Get solid on Airflow DAGs first.
Phase 4 project: Build an Airflow DAG that automatically retrains your model on a schedule, compares the new model's accuracy to the previous production model, and only promotes it if it improves.
Production Monitoring
Deploying a model is not the finish line — it's the starting gun. Production models degrade over time as the real world changes. This is called model drift, and it's the #1 cause of silent ML failures.
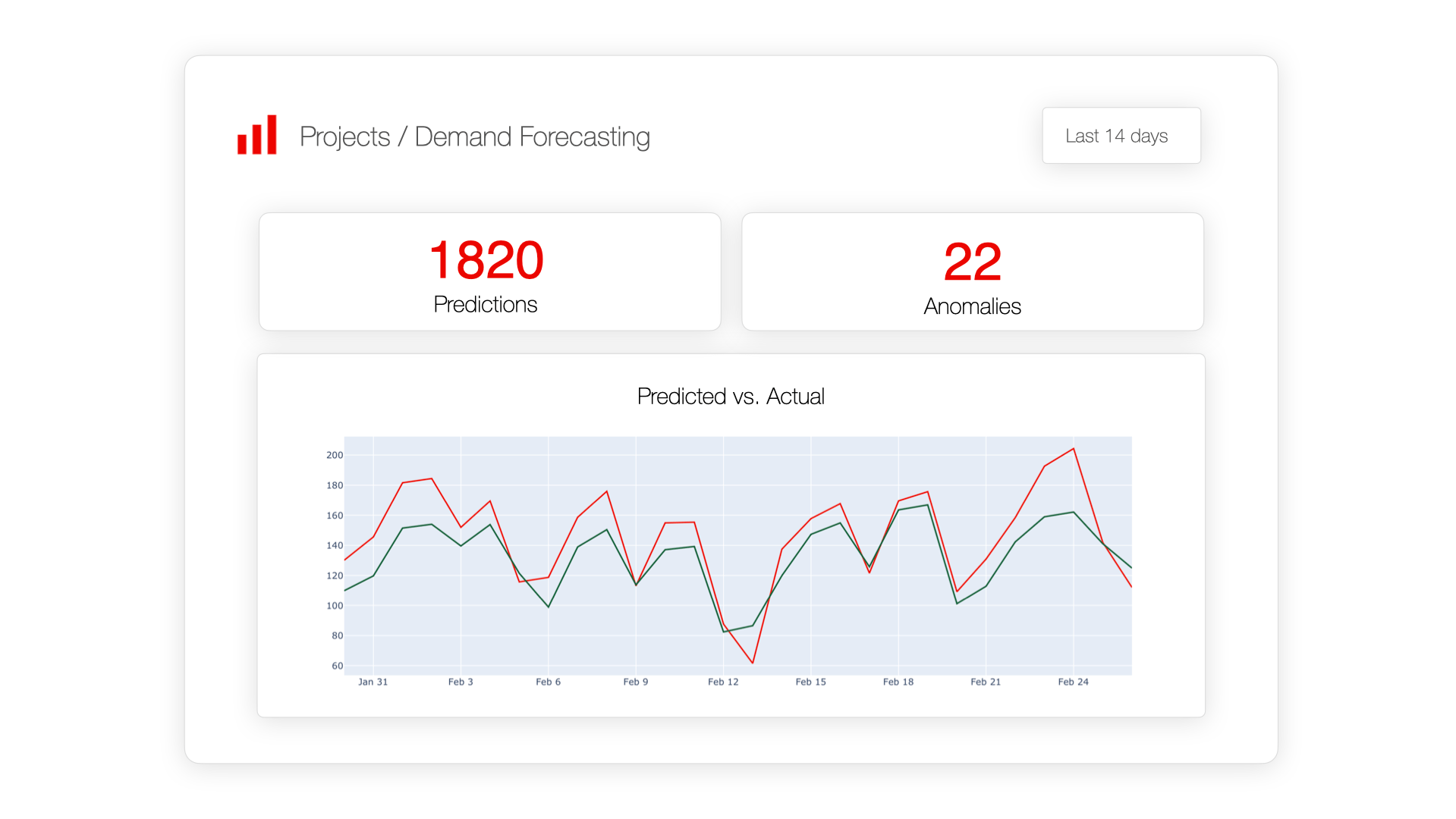
Figure 5: Model monitoring dashboard — tracking predictions vs actuals over time
Data Drift Detection
Monitor input feature distributions over time. When they shift significantly, it's time to retrain.
Concept Drift
The relationship between features and labels changes. Harder to detect — requires ground truth labels with a delay.
Prediction Logging
Log every prediction your model makes — input features, output prediction, timestamp, and model version.
Phase 5 project: Add prediction logging to your FastAPI server. Set up a simple Grafana dashboard showing request volume, average confidence, and prediction distribution over time.
Advanced Topics
Once you're solid on the core loop — train, track, deploy, monitor — these advanced topics will make you genuinely exceptional. In 2026, LLMOps in particular is the hottest sub-specialty in the field.
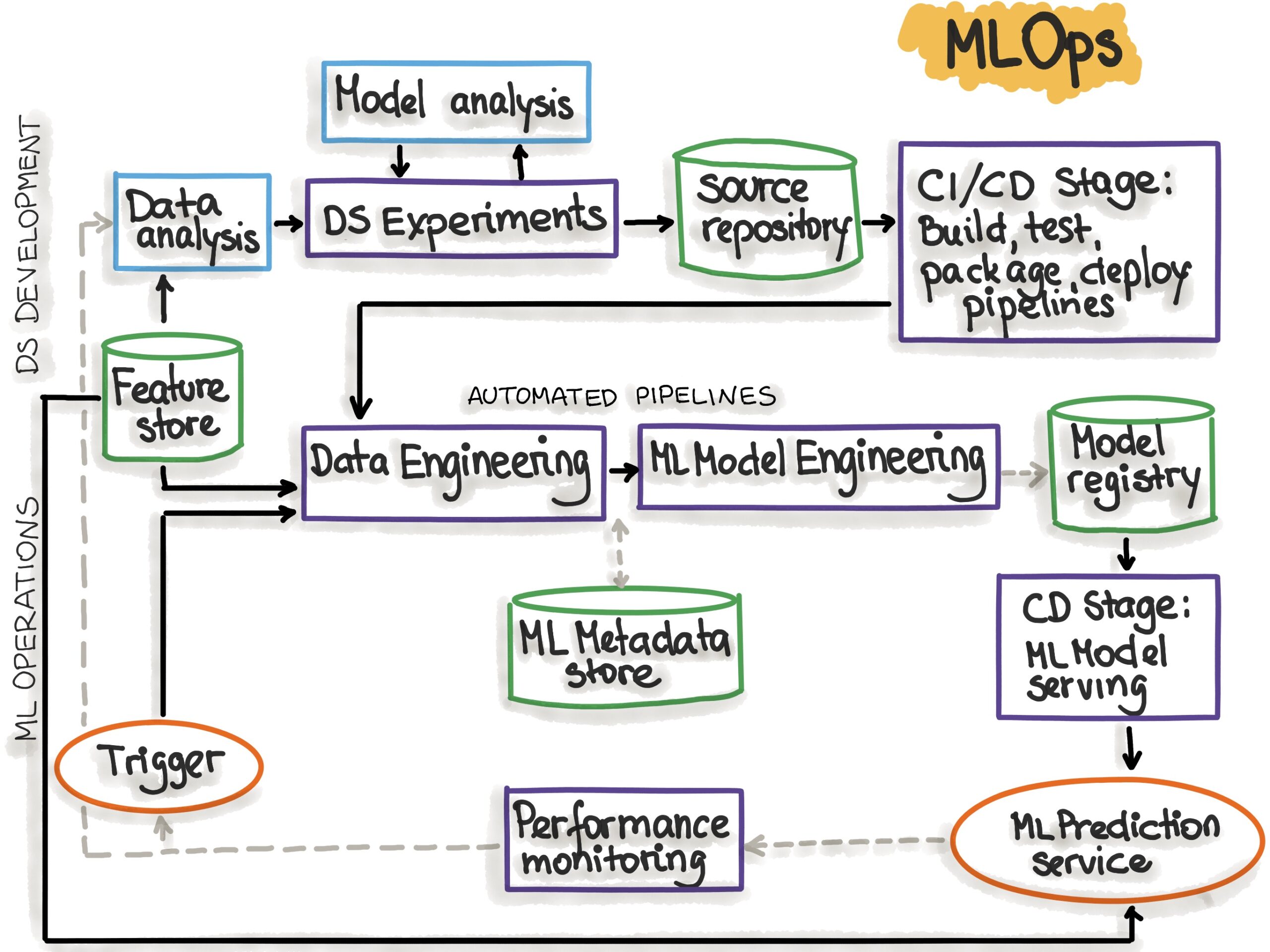
Figure 6: The complete MLOps lifecycle — from data analysis to production monitoring
LLMOps
Deploy, evaluate, and monitor large language models. Prompt versioning, eval frameworks (Ragas, LangSmith), and cost monitoring.
Feature Stores
Feast, Tecton, or Databricks Feature Store. Share features across teams, guarantee train-serve consistency.
Model Governance
Model cards, audit trails, bias detection, and compliance. Increasingly required by enterprise clients and regulators.
2026 Trend: LLMOps is converging with traditional MLOps. Engineers who can manage both classical ML models and LLM-based systems are commanding 20–30% salary premiums.
Free Learning Resources
Fast.ai Practical Deep Learning
Best practical ML course on the internet. Top-down, hands-on, free.
Coursera MLOps Specialization
Andrew Ng's MLOps course. Covers the full production ML lifecycle.
MLflow Official Docs
The official MLflow docs are genuinely well-written. The quickstart gets you running in 10 minutes.
Designing Machine Learning Systems
Chip Huyen's book. The production ML bible.
Kaggle
Free datasets, free GPU, free notebooks. Use it for every hands-on project.
MLOps Community (Slack)
10,000+ ML engineers. Ask questions, share projects, find job referrals.
Getting Hired: Portfolio, Open Source, Network
Technical skills get you interviews. Portfolio projects get you offers. Here's the three-part strategy that works.
Build a Public Portfolio
Every phase of this roadmap produces a project. Put all of them in public GitHub repos with clean READMEs, architecture diagrams, and documented design decisions.
Contribute to Open Source
MLflow, Airflow, and Evidently AI all accept contributions. Start with documentation fixes or small bug reports.
Build in Public on LinkedIn
Post one LinkedIn update per week documenting what you learned. Recruiters find you. Offers come inbound.
The fastest path to your first MLOps role: Find a company that does ML but doesn't have dedicated MLOps. Offer to set up MLflow tracking and a basic deployment pipeline. Do it for free as a portfolio project. Then apply full-time.
All Articles in This Series
MLflow vs Weights & Biases — Full Comparison (2026)
Which experiment tracking tool actually saves engineering time?
7 Best W&B Alternatives (Free & Paid) for 2026
Budget-friendly experiment tracking tools that actually work.
Neptune AI Alternatives — Migration Guide
Where to go after the Neptune shutdown.
ClearML Review: Is This Open Source Platform Worth It?
Full MLOps platform analysis.
10 Best MLOps Tools for Machine Learning Teams (2026)
The complete guide to the MLOps landscape.
MLflow vs ClearML — Which Open Source MLOps Tool Wins?
Deep dive into two open source giants.
How to Deploy a Machine Learning Model with Docker and MLflow
From training to live API in 45 minutes.
Kubeflow vs Airflow — Which Pipeline Tool Should You Use?
Data engineering standard vs ML-native platform.
MLflow Tutorial: Track ML Experiments in 20 Minutes
The fastest MLflow tutorial anywhere.
MLOps Roadmap 2026: How to Become an ML Engineer ← You are here
The complete 6-month plan, resources, and career advice.
Get the Free MLOps Roadmap PDF
A printable, one-page version of this roadmap — with resources, project checklists, and salary benchmarks. Yours free.
No spam, ever. Unsubscribe in one click.