Looking for a complete LLMOps tutorial for beginners? This guide covers everything you need to know to deploy, monitor, and optimize Large Language Models in production — from prompt versioning to cost control, with real code examples.
This LLMOps tutorial is designed for ML engineers, data scientists, and developers who want to move LLM applications from prototype to production. No prior LLMOps experience required.
Table of Contents
- 01What is LLMOps and Why It Matters in 2026Essential
- 02LLMOps vs MLOps: Key DifferencesComparison
- 03Core Components of an LLMOps StackArchitecture
- 04Essential LLMOps Tools OverviewTools
- 05Step-by-Step: Build a RAG Pipeline with TracingTutorial
- 06Cost Management: Track, Optimize, ControlEconomics
- 07Frequently Asked QuestionsFAQ
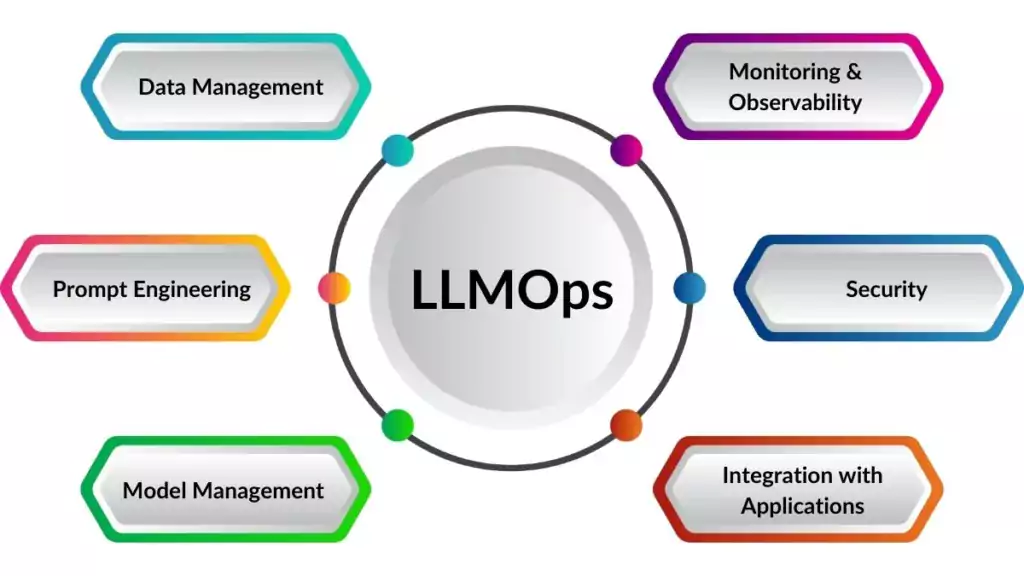
Figure 1: The six core components of an LLMOps stack — from prompt management to feedback loops
01 What is LLMOps and Why It Matters in 2026
LLMOps (Large Language Model Operations) is the set of practices, tools, and workflows used to deploy, monitor, and maintain LLM-powered applications in production. Think of it as DevOps — but purpose-built for the era of generative AI.
As of 2026, LLMs have moved from research curiosities to mission-critical infrastructure. Teams are running millions of API calls per day, managing complex RAG pipelines, and serving customers in real time. Without proper operations practices, costs spiral, quality degrades silently, and debugging becomes nearly impossible.
HIGH RISK
MEDIUM
HIGH RISK
LLMOps is not just about infrastructure. It's about maintaining quality, reliability, and cost-efficiency as your prompt evolves, your data changes, and your user base grows. In 2026, having LLMOps in place is the difference between an AI product and an AI experiment.
02 LLMOps vs MLOps: Key Differences
If you have a background in traditional machine learning, you might wonder: why not just use MLOps? The short answer is that LLMs introduce entirely new operational concerns that classic ML pipelines never had to handle.
Figure 2: LLMOps vs MLOps — understanding the key differences in 2026
| Traditional MLOps | LLMOps (2026) |
|---|---|
| Feature engineering & model training cycles | Prompt versioning — prompts are your "model weights" |
| Model accuracy metrics (F1, AUC, RMSE) | LLM-specific evals: faithfulness, relevancy, coherence | Compute cost tracked per training run | Token-level cost tracking per request, per user |
| Data drift detection on tabular features | Output drift: hallucination rate, tone, format drift |
Many teams apply MLOps tooling to LLM workloads and wonder why it doesn't work. The fundamental difference: in classical ML, the "intelligence" lives in model weights. In LLMs, a huge portion of behavior is encoded in your prompts, context, and retrieval logic — and those change far more frequently.
03 Core Components of an LLMOps Stack
Version-control your prompts like code. Track changes, run A/B tests, and roll back when a new prompt hurts quality.
Measure retrieval quality: Are you fetching the right context? Is the LLM using it faithfully? Tools like Ragas.
Full-stack tracing of every LLM call, chain step, and tool invocation. See latency, token usage, and outputs.
Automated safety checks on inputs and outputs: block jailbreaks, redact PII, detect hallucinations.
Per-request token accounting. Attribute costs to users, features, or tenants. Set budget alerts.
Collect human ratings and implicit signals. Feed them back into prompt improvement cycles.
04 Essential LLMOps Tools Overview
Built by the LangChain team. Best-in-class tracing for LangChain and LangGraph apps.
- Tracing every chain step
- LLM evaluation metrics
- Prompt playground
Open-source framework for evaluating RAG pipelines. Measures faithfulness, answer relevance, context precision.
- Automated RAG metrics
- Works with any LLM
- CI/CD integration
Drop-in proxy for any OpenAI/Anthropic call. Logs every request, tracks token costs, and monitors latency.
- 5-minute setup
- Per-user cost tracking
- Custom properties
End-to-end LLM evaluation platform with experiment tracking and scoring functions.
- Experiment tracking
- Prompt testing
- Dataset management
Starting out? Use Helicone for instant cost visibility (5 min setup), LangSmith for tracing your chains, and Ragas to evaluate your RAG retrieval. That covers 80% of your LLMOps needs with minimal overhead.
05 Step-by-Step: Build a RAG Pipeline with Tracing
Let's build a minimal but production-instrumented RAG pipeline. We'll use LangChain for orchestration, Chroma as our vector store, and LangSmith for tracing every step.
5.1 Set Up Your Environment
|
1 |
pip install langchain langchain-openai langchain-chroma langsmith |
5.2 Build the RAG Chain with Tracing
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import os from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_chroma import Chroma from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langsmith import traceable # Configure LangSmith tracing os.environ["LANGCHAIN_TRACING_V2"] = "true" os.environ["LANGCHAIN_PROJECT"] = "llmops-demo" # Build the retriever vectorstore = Chroma.from_documents(documents=docs, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever(search_kwargs={"k": 4}) # Versioned prompt prompt = ChatPromptTemplate.from_messages([ ("system", "Answer using ONLY the context below.\n\n{context}"), ("human", "{question}") ]) llm = ChatOpenAI(model="gpt-4o", temperature=0) # LCEL chain — LangSmith auto-traces every node rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | llm ) @traceable(run_type="chain", name="rag_query") def query(question: str) -> str: response = rag_chain.invoke(question) return response.content |
5.3 Add Ragas Evaluation
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from ragas import evaluate from ragas.metrics import faithfulness, answer_relevancy from datasets import Dataset eval_data = { "question": questions, "answer": generated_answers, "contexts": retrieved_contexts, "ground_truth": ground_truths } result = evaluate( Dataset.from_dict(eval_data), metrics=[faithfulness, answer_relevancy] ) # Gate your deployment assert result["faithfulness"] >= 0.85, "Faithfulness too low — check prompt" print(result.to_pandas()) |
After each prompt change, re-run your evaluation suite. If faithfulness drops below your threshold (e.g., 0.85), don't deploy. This is your LLMOps quality gate.
06 Cost Management: Track, Optimize, Control
Token costs are the silent killer of LLM startups. A feature that costs $10/day in dev can cost $3,000/month in production. Here's how to keep your bill in check.
| Strategy | Description | Savings |
|---|---|---|
| Prompt compression | Reduce system prompt length | 15–40% |
| Model routing | Route simple queries to smaller/cheaper models | 50–80% |
| Semantic caching | Cache LLM responses for similar queries | 20–60% |
| Context window tuning | Reduce retrieved chunks, trim conversation history | 20–35% |
| Batch API | Use async batch endpoints for non-real-time tasks | 50% |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from openai import OpenAI # Just swap the base_url — all calls are logged automatically client = OpenAI( api_key=OPENAI_API_KEY, base_url="https://oai.helicone.ai/v1", default_headers={ "Helicone-Auth": f"Bearer {HELICONE_API_KEY}", "Helicone-Property-Feature": "rag-qa", "Helicone-Property-User-Id": user_id } ) # Manual cost calculation COST_PER_1K = { "gpt-4o": {"input": 0.0025, "output": 0.01}, "gpt-4o-mini": {"input": 0.00015, "output": 0.0006}, } def calculate_cost(model, usage): rates = COST_PER_1K[model] return (usage.prompt_tokens / 1000 * rates["input"] + usage.completion_tokens / 1000 * rates["output"]) |
Classify incoming queries by complexity. Route simple factual questions (70% of traffic) to a cheap small model. Route reasoning tasks (25%) to a mid-tier model. Reserve your flagship model for the genuinely hard cases (5%). This alone can cut your monthly bill by 60–70% with no quality loss.
07 Frequently Asked Questions
What's the difference between LLMOps and MLOps?
LLMOps focuses on prompt versioning, RAG evaluation, token cost tracking, and hallucination detection. MLOps focuses on model training, feature engineering, and traditional drift detection. In 2026, LLMOps is an extension of MLOps for generative AI workloads.
What LLMOps tools should I start with as a beginner?
Start with Helicone for cost tracking (5-minute setup), LangSmith for tracing your LangChain apps (free tier), and Ragas for RAG evaluation (open source). This stack covers 80% of beginner LLMOps needs.
How do I monitor LLM cost effectively?
Use a proxy like Helicone that intercepts every API call and logs token usage. Set per-user and per-feature budgets. Implement model routing to send simple queries to cheaper models. Semantic caching can also dramatically reduce duplicate API calls.
How do I evaluate RAG pipeline quality?
Use Ragas metrics: faithfulness (does the answer use the retrieved context?), answer relevancy (is the answer relevant to the question?), and context precision/recall (did we retrieve the right chunks?). Set thresholds (e.g., faithfulness > 0.85) as deployment gates.
Can I use MLflow for LLMOps?
MLflow 2.x has limited LLM support (logging prompts and responses). For full LLMOps, you'll need specialized tools like LangSmith for tracing or Helicone for cost tracking. MLflow works best as a model registry for fine-tuned LLMs, not for API-based LLM applications.
📖 External resources: LangSmith • Ragas Documentation • Helicone • Braintrust
📖 ML Pipeline Tutorial • Model Drift Detection • ML Engineer Career Guide